

Article initialement publié en 2018, mis à jour en avril 2026.
À l’heure de l’ouverture des données et du « tout API », il devient de plus en plus simple d’exploiter, transformer et réutiliser certaines informations mises à disposition. De nouveaux services émergent, parfois très utiles, parfois franchement discutables, mais ils émergent.
Beaucoup voient dans l’ouverture des données une manière de favoriser de nouveaux usages, de faire naître des services innovants, ou, plus prosaïquement, de mieux valoriser ce fameux « nouvel or noir ».
Pour d’autres, la mise à disposition des données reste plus difficile à envisager. Par manque d’intérêt, parfois. Par stratégie, aussi : garder la main sur ses données, c’est encore souvent garder la main sur ses utilisateurs, en limitant leur capacité à réutiliser, croiser ou faire circuler l’information.
Le web scraping apparaît alors comme une réponse très concrète à une situation toute simple : des données existent, elles sont visibles sur le web, mais elles ne sont pas proposées dans un format facilement réexploitable.
Le web scraping est, au fond, une manière de redonner du pouvoir aux utilisateurs : on extrait une information publiée sur le web pour la restructurer et la rendre exploitable par un système informatique.
On développe alors des robots dont l’objectif est d’automatiser la collecte d’information, la navigation ou certaines saisies dans des applications web ou métier. Dans leur version plus ambitieuse, ces robots peuvent s’inscrire dans des logiques de workflow, de case management ou de RPA.
Dans cet article, nous allons rester concentrés sur la partie scraping. Nous allons répondre à une question très simple : comment extraire automatiquement de l’information d’un site internet qui n’a pas ouvert ses données ?
Pour cela, nous allons travailler avec Puppeteer sur le site de démonstration https://quotes.toscrape.com/js/, une version d’un petit site de citations dont le contenu est rendu côté navigateur.
Quelques usages du web scraping
Avant de mettre les mains dans le code, prenons deux minutes pour regarder à quoi peut bien servir cette technique.
Parmi les usages les plus fréquents, on retrouve :
- l’ouverture de données, lorsqu’on veut rendre exploitable une information publiée, mais difficilement réutilisable en l’état ;
- l’interopérabilité, lorsqu’il faut faire dialoguer deux systèmes qui n’ont jamais été pensés pour se parler ;
- la mobilité, lorsqu’on veut rendre accessible depuis d’autres terminaux une application web qui n’a pas été conçue pour cela ;
- l’archivage de sites internet, qu’il s’agisse de récupérer du HTML, des ressources ou de prendre des copies d’écran ;
- la surveillance de mises à jour, de prix, de disponibilités ou de publications.
Autrement dit, le web scraping n’est pas seulement une technique de collecte. C’est aussi une manière de redonner de la prise sur une information qui existe déjà, mais qui reste enfermée dans une interface.
Les différents moyens de publier de l’information sur un site internet
Entrons maintenant dans le vif du sujet. Avant de collecter la moindre donnée, nous devons observer comment fonctionne le site auquel nous nous attaquons, et plus précisément la manière dont l’information y est publiée.
Pour simplifier, je dirais qu’il existe deux grandes manières d’afficher de l’information sur un site internet :
- de manière statique : le contenu utile est déjà présent dans le HTML renvoyé par le serveur ;
- de manière dynamique : la page principale est surtout une coquille, et le contenu est injecté ensuite par du JavaScript exécuté côté client.
Le site Quotes to Scrape a justement la bonne idée de proposer les deux approches. C’est très pratique pour comprendre la différence.
Dans sa version statique, un simple wget suffit :
wget https://quotes.toscrape.com/Si vous ouvrez ensuite le fichier récupéré, vous verrez les citations dans le HTML. Ce n’est pas forcément très beau, mais l’essentiel est là : le texte est présent, donc exploitable. Inutile, dans ce cas, de charger un navigateur complet.

Si l’on prend maintenant la version JavaScript du même site et qu’on lance exactement la même commande :
wget https://quotes.toscrape.com/js/Cette fois, le résultat est beaucoup plus pauvre. Et c’est normal : ici, le contenu n’est pas fourni directement par le serveur. Il est généré ensuite par du JavaScript. Notre premier outil de scraping, wget, ne sait pas exécuter ce code.
C’est là tout l’intérêt d’une solution qui s’appuie sur un vrai navigateur.

Quelques exemples d’outils de web scraping en 2026
Pour des pages simples, wget et curl rendent encore de fiers services. Ils vont droit au but, récupèrent le HTML brut et ne s’encombrent pas du reste.
Dès qu’un site s’appuie sur du JavaScript pour afficher son contenu, il faut changer de catégorie d’outils. Dans ce cas, on veut un moteur de navigation complet, capable de charger la page, d’exécuter le JavaScript et de nous laisser récupérer le DOM final.
C’est précisément ce que fait Puppeteer. Historiquement, on parlait beaucoup de Chromium dans ce type de tutoriel. Aujourd’hui, l’installation standard de Puppeteer télécharge surtout un navigateur compatible prêt à l’emploi, ici Chrome for Testing.
En cas d’ennui de configuration, je vous renvoie vers le Troubleshooting guide de puppeteer avec toujours la commande magique :
ldd chrome | grep notBien sûr, Puppeteer n’est pas seul au monde. Selenium existe toujours, Playwright s’est imposé dans de nombreux projets, et certains outils comme Cheeriojs et BS4 pour python restent très utilisés encore aujourd’hui.
Mais pour ce tutoriel, Puppeteer reste un excellent compagnon de route.
Mise en œuvre
Comme annoncé au début de l’article, nous allons répondre à la question « Comment extraire automatiquement de l’information d’un site internet qui n’a pas ouvert ses données ? » par la pratique.
Installation de Node.js
Je ne vais pas détailler ici toute l’installation de Node.js, car elle dépend beaucoup de votre environnement. En revanche, en 2026, il faut partir sur une base récente.
A noter que node embarque NPM, le gestionnaire de paquets node.
Vous pouvez déjà vérifier ce que vous avez sous la main :
node -v
npm -vEn cas de besoin, la procédure est détaillée ici.
Initialisation du projet
L’initialisation du projet se fait dans un répertoire dédié :
mkdir marionnette
cd marionnette
npm init -yVoici ce que fait ce bloc :
mkdir marionnettecrée un répertoire de travail ;cd marionnettenous place dedans ;npm init -yinitialise rapidement le projet et génère unpackage.json.
Et comme vous avez été poli, vous avez répondu oui par défaut à toutes les questions avec -y.
Installation de Puppeteer
Pour cet exercice, nous allons utiliser Puppeteer. Puppeteer est une bibliothèque Node.js qui permet de piloter un navigateur avec du JavaScript.
L’installation se fait très simplement :
npm i puppeteerCréons aussi un répertoire pour nos captures :
mkdir screenshotsIci, rien de particulièrement subtil : on prépare simplement l’endroit où nous allons stocker nos copies d’écran.
Notre Hello World
La première étape consiste à vérifier que tout fonctionne. Pour cela, nous allons prendre une copie d’écran de la page JavaScript du site de démonstration.
Créons un fichier capture.js contenant le code suivant :
const puppeteer = require('puppeteer');
async function capture() {
const browser = await puppeteer.launch({ headless: true });
try {
const page = await browser.newPage();
await page.setViewport({ width: 1440, height: 1800 });
await page.goto('https://quotes.toscrape.com/js/', {
waitUntil: 'domcontentloaded',
});
await page.waitForSelector('.quote', { timeout: 10000 });
await page.screenshot({
path: 'screenshots/quotes-to-scrape.png',
fullPage: true,
});
} finally {
await browser.close();
}
}
capture().catch((error) => {
console.error(error);
process.exit(1);
});Voici ce que fait le code :
- il importe Puppeteer ;
- il déclare une fonction asynchrone
capture; - il lance une instance du navigateur en mode headless ;
- il ouvre une nouvelle page ;
- il définit une taille d’affichage confortable ;
- il navigue vers la page cible ;
- il attend explicitement qu’une citation soit présente dans le DOM ;
- il prend une capture d’écran de la page complète ;
- il ferme proprement le navigateur, même en cas d’erreur ;
- enfin, il exécute la fonction et journalise l’erreur éventuelle.
Ici, j’attends le sélecteur .quote plutôt que d’utiliser un délai arbitraire ou de me reposer sur networkidle2. C’est plus propre, plus lisible et plus robuste.
node capture.jsLançons ensuite le script :
Si tout se passe bien, vous obtenez une capture dans le répertoire screenshots.
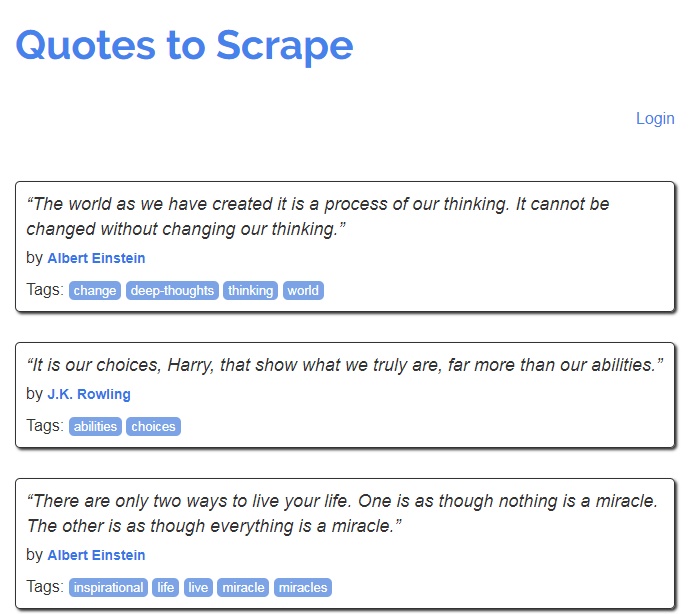
Et là, TADAAA, nous venons de confirmer que notre navigateur automatisé fonctionne.
Scraping du site internet de citations
Dans cette seconde partie, nous allons extraire le contenu du site de citations sous forme de données.
Le site que nous observons est une page listant des citations. Chaque citation est composée d’un texte, d’un auteur et d’une série de mots-clés. Le site est paginé, mais dans cet article, je vais laisser la pagination de côté pour me concentrer sur l’extraction du contenu de la page.
Pour commencer, et par praticité, nous allons définir une citation comme ceci :
function Quote(text, author, tags) {
this.text = text;
this.author = author;
this.tags = tags;
}Ce petit morceau de code nous donne une structure claire pour stocker les résultats du scraping : une citation aura un texte, un auteur et une liste de tags.
Avant de nous lancer dans l’écriture du code, nous allons inspecter la source de la page afin de déterminer comment sont structurées les citations dans le contenu de la page.
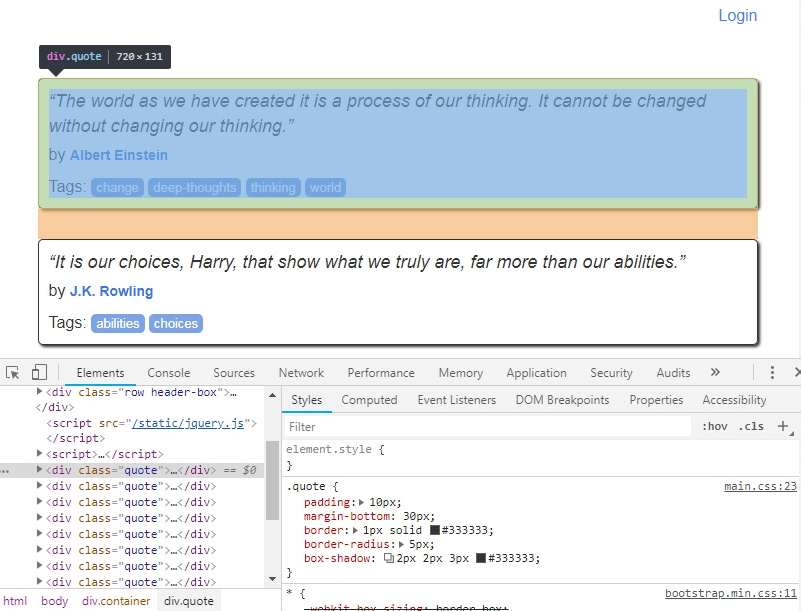
.quote.On remarque alors que chaque citation est contenue dans une div qui porte la classe quote. Nous allons donc lancer une requête dans le contenu de la page pour obtenir toutes les div.quote de notre document et enregistrer cela dans un tableau :
const elements = await page.$$('div.quote');Ici, page.$$() retourne tous les éléments correspondant au sélecteur CSS fourni. Si rien n’est trouvé, on obtient simplement un tableau vide.
Nous allons ensuite parcourir chacun de ces éléments pour aller chercher le texte, l’auteur et les tags.
Le code source de la page nous donne :
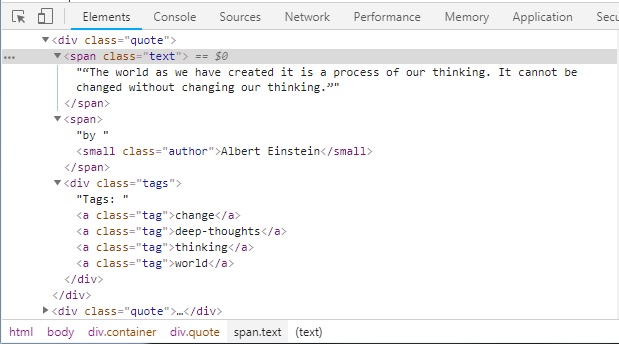
Ce qui nous permet d’écrire ce code:
for (const element of elements) {
const text = await element.$eval('.text', (s) => s.textContent.trim());
const author = await element.$eval('.author', (s) => s.textContent.trim());
const tags = await element.$$eval('.tag', (ar) =>
ar.map((a) => a.textContent.trim())
);
console.log(`${text} - ${author}`);
}Voici ce que fait ce bloc :
- on boucle sur chaque citation de la page ;
- on récupère le texte via le sélecteur
.text; - on récupère l’auteur via le sélecteur
.author; - on récupère tous les tags via le sélecteur
.tag; - on nettoie les espaces inutiles avec
trim(); - enfin, on logue le texte et l’auteur pour vérifier que tout fonctionne.
Une fois les briques en place, il ne nous reste plus qu’à stocker le contenu dans un tableau. Le fichier complet scrape.js devient :
const puppeteer = require('puppeteer');
function Quote(text, author, tags) {
this.text = text;
this.author = author;
this.tags = tags;
}
async function scrape() {
const browser = await puppeteer.launch({ headless: true });
try {
const page = await browser.newPage();
await page.setViewport({ width: 1440, height: 1800 });
await page.goto('https://quotes.toscrape.com/js/', {
waitUntil: 'domcontentloaded',
});
await page.waitForSelector('.quote', { timeout: 10000 });
const elements = await page.$$('div.quote');
const mydata = [];
for (const element of elements) {
const text = await element.$eval('.text', (s) =>
s.textContent.trim()
);
const author = await element.$eval('.author', (s) =>
s.textContent.trim()
);
const tags = await element.$$eval('.tag', (ar) =>
ar.map((a) => a.textContent.trim())
);
const item = new Quote(text, author, tags);
mydata.push(item);
}
console.log(mydata);
} finally {
await browser.close();
}
}
scrape().catch((error) => {
console.error(error);
process.exit(1);
});Voici ce que fait le fichier complet :
- il importe Puppeteer ;
- il définit la structure
Quote; - il lance le navigateur et ouvre une page ;
- il navigue vers la page cible ;
- il attend que les citations soient bien présentes ;
- il récupère tous les blocs
.quote; - il parcourt chaque bloc pour en extraire les données ;
- il pousse chaque citation dans un tableau ;
- il logue les résultats dans la console ;
- il ferme le navigateur, même si une erreur survient.
Vous pouvez tester cela très simplement :
node scrape.jsVous devriez obtenir en sortie une liste de citations structurées, avec leur texte, leur auteur et leurs tags.
[ Quote {
text:
'“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
author: 'Albert Einstein',
tags: [ 'change', 'deep-thoughts', 'thinking', 'world' ] },
Quote {
text:
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
author: 'J.K. Rowling',
tags: [ 'abilities', 'choices' ] },
Quote {
text:
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
author: 'Albert Einstein',
tags: [ 'inspirational', 'life', 'live', 'miracle', 'miracles' ] },
Quote {
text:
'“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”',
author: 'Jane Austen',
tags: [ 'aliteracy', 'books', 'classic', 'humor' ] },
Quote {
text:
'“Imperfection is beauty, madness is genius and it\'s better to be absolutely ridiculous than absolutely boring.”',
author: 'Marilyn Monroe',
tags: [ 'be-yourself', 'inspirational' ] },
Quote {
text:
'“Try not to become a man of success. Rather become a man of value.”',
author: 'Albert Einstein',
tags: [ 'adulthood', 'success', 'value' ] },
Quote {
text:
'“It is better to be hated for what you are than to be loved for what you are not.”',
author: 'André Gide',
tags: [ 'life', 'love' ] },
Quote {
text:
'“I have not failed. I\'ve just found 10,000 ways that won\'t work.”',
author: 'Thomas A. Edison',
tags: [ 'edison', 'failure', 'inspirational', 'paraphrased' ] },
Quote {
text:
'“A woman is like a tea bag; you never know how strong it is until it\'s in hot water.”',
author: 'Eleanor Roosevelt',
tags: [ 'misattributed-eleanor-roosevelt' ] },
Quote {
text: '“A day without sunshine is like, you know, night.”',
author: 'Steve Martin',
tags: [ 'humor', 'obvious', 'simile' ] } ]Nous disposons donc maintenant des citations sous une forme exploitable, et pouvons les utiliser dans un projet plus large.
Bonus track : mettre à disposition les données via une API REST
Vous êtes arrivé jusqu’ici. Bravo.
Pour la suite, nous allons exposer sous une forme structurée les données fraîchement collectées. Pour cela, nous allons utiliser Express.
Depuis le terminal, installons Express :
npm i expressNous allons ensuite créer une petite structure de projet :
mkdir routes
mkdir controllers
mkdir models
mv scrape.js modelsVoici le rôle de ces répertoires :
routescontiendra les points d’entrée de l’application ;controllerscontiendra la logique de traitement ;modelscontiendra la logique liée aux données, ici le scraping lui-même.
Le fichier models/scrape.js ne va pas beaucoup changer, mais il doit désormais retourner les données et être exporté pour être utilisé par le contrôleur.
Voici sa nouvelle version :
const puppeteer = require('puppeteer');
function Quote(text, author, tags) {
this.text = text;
this.author = author;
this.tags = tags;
}
async function scrape(url = 'https://quotes.toscrape.com/js/') {
const browser = await puppeteer.launch({ headless: true });
try {
const page = await browser.newPage();
await page.setViewport({ width: 1440, height: 1800 });
await page.goto(url, {
waitUntil: 'domcontentloaded',
});
await page.waitForSelector('.quote', { timeout: 10000 });
const rawQuotes = await page.$$eval('.quote', (nodes) =>
nodes.map((node) => ({
text: node.querySelector('.text')?.textContent?.trim() ?? '',
author: node.querySelector('.author')?.textContent?.trim() ?? '',
tags: Array.from(node.querySelectorAll('.tag'), (tag) =>
tag.textContent?.trim() ?? ''
),
}))
);
const mydata = rawQuotes.map(
({ text, author, tags }) => new Quote(text, author, tags)
);
return mydata;
} finally {
await browser.close();
}
}
module.exports = scrape;Voici ce qui change :
- la fonction
scrapeaccepte maintenant une URL en paramètre ; - le code est devenu un peu plus compact en supprimant la boucle explicite et en demandant à Puppeteer de parcourir directement tous les éléments
.quote, d’en extraire les données utiles, puis de reconstruire ensuite nos objetsQuote; - la fonction retourne le tableau
mydataau lieu de se contenter de l’afficher ; - elle exporte la fonction avec
module.exportspour qu’un autre module puisse l’utiliser.
Dans le répertoire controllers, créons maintenant quoteController.js :
'use strict';
const scrape = require('../models/scrape');
exports.listAllQuotes = async function (req, res) {
const url = req.query.url || 'https://quotes.toscrape.com/js/';
try {
const response = await scrape(url);
res.status(200).json({
source: url,
count: response.length,
results: response,
});
} catch (error) {
res.status(500).json({
error: 'Scraping impossible',
details: error.message,
});
}
};Voici ce que fait ce contrôleur :
- il importe la fonction
scrape; - il déclare une méthode
listAllQuotes; - il lit une éventuelle URL passée en paramètre de requête ;
- il déclenche le scraping ;
- il retourne une réponse JSON structurée si tout se passe bien ;
- sinon, il retourne une erreur HTTP 500 avec un message explicite.
Petit aparté sur req.query.url
C’est souvent là que la question arrive, et elle est légitime : Est-ce que je peux passer une url en paramètre ?
Quand vous appelez une URL du type :
http://localhost:8080/quotes?url=https%3A%2F%2Fquotes.toscrape.com%2Fjs%2Ftout ce qui se trouve après le ? correspond à la query string. Dans Express, ces paramètres sont accessibles via req.query. Cela signifie que req.query.url permet de récupérer la valeur transmise dans le paramètre url.
Autrement dit, dans notre contrôleur, cette ligne :
const url = req.query.url || 'https://quotes.toscrape.com/js/';veut simplement dire : « si une URL est fournie dans la requête, je l’utilise ; sinon, je retombe sur l’URL par défaut ».
Il faut simplement garder un réflexe sain : cette valeur vient de l’extérieur. Dans un vrai projet, on évite donc de faire confiance aveuglément à une URL fournie par l’utilisateur. On la valide, on la filtre, voire on limite les domaines autorisés.
Créons ensuite le fichier routes/quoteRoute.js :
'use strict';
module.exports = function (router) {
const quoteCtl = require('../controllers/quoteController');
router.route('/quotes').get(quoteCtl.listAllQuotes);
};Le rôle de ce fichier est très simple : lorsque le point d’entrée /quotes est appelé en GET, l’application délègue le traitement au contrôleur listAllQuotes, qui déclenche lui-même le scraping et retourne les résultats au format JSON.
Enfin, pour démarrer l’application, créons server.js à la racine du projet :
const express = require('express');
const app = express();
const router = express.Router();
const port = process.env.PORT || 8080;
app.use(express.urlencoded({ extended: true }));
app.use(express.json());
const routes = require('./routes/quoteRoute');
routes(router);
router.use((req, res) => {
res.status(404).json({
error: 'Route introuvable',
url: req.originalUrl,
});
});
app.use('/', router);
app.listen(port, () => {
console.log(`Quotes RESTful API server started on: ${port}`);
});Voici ce que fait ce fichier :
- il crée l’application Express ;
- il prépare un routeur ;
- il active la lecture des corps de requête JSON et URL-encodés ;
- il enregistre les routes de l’application ;
- il gère un cas simple de route introuvable ;
- il démarre le serveur sur le port
8080par défaut.
Dans cette version, je n’utilise plus body-parser explicitement. Express fournit déjà ce qu’il faut pour ce cas d’usage simple.
Il ne reste plus qu’à tester.
Pour cela, nous lançons l’application de la manière suivante :
node server.jsLe serveur est correctement démarré si vous voyez apparaître ceci :
Quotes RESTful API server started on: 8080Avec votre navigateur, rendez-vous ensuite à l’adresse :
http://localhost:8080/quotesVous devriez obtenir une réponse JSON contenant la liste des citations extraites.
{
"source": "https://quotes.toscrape.com/js/",
"count": 10,
"results": [
{
"text": "“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”",
"author": "Albert Einstein",
"tags": [
"change",
"deep-thoughts",
"thinking",
"world"
]
},
{
"text": "“It is our choices, Harry, that show what we truly are, far more than our abilities.”",
"author": "J.K. Rowling",
"tags": [
"abilities",
"choices"
]
},
{
"text": "“A day without sunshine is like, you know, night.”",
"author": "Steve Martin",
"tags": [
"humor",
"obvious",
"simile"
]
}
]
}Et si vous souhaitez passer l’URL cible en paramètre, vous pouvez appeler :
http://localhost:8080/quotes?url=https%3A%2F%2Fquotes.toscrape.com%2Fjs%2FConclusion
Vous venez d’extraire automatiquement vos premières données structurées à partir d’informations publiées sur un site web généré en JavaScript. Vous avez aussi vu qu’une fois ces données récupérées, il devient possible de les retravailler, de les comparer, de les réinjecter dans d’autres applications, voire de les réexposer au travers d’une petite API.
Sachez tout de même que si vous cherchez à automatiser le téléchargement de fichier, il y a toujours une limitation qui n’est pas des moindres : il est impossible de télécharger un fichier avec Puppeteer pour l’instant.
Évidemment, cette démonstration ouvre immédiatement sur plusieurs pistes d’amélioration :
- la mise en cache des données, pour éviter de solliciter inutilement le site distant ;
- la prise en compte du temps de traitement, car un vrai scénario de scraping peut être long ;
- la validation des données d’entrée et de sortie ;
- la gestion des erreurs réseau, des modifications de structure HTML et des comportements imprévus ;
- la pagination, que nous avons volontairement laissée de côté ici.
Le web scraping n’a pas disparu avec la généralisation des API. Il reste un outil d’interopérabilité, de veille, d’archivage et parfois, tout simplement, une manière très pratique de redonner de la prise sur une information publiée mais peu réutilisable.
À lire aussi sur le site
- Adoptez le CMMN, la notation du Case Management
- Introduction à la blockchain des archivistes
- Le SHA1 est mort, vive le SHA1
- Hacker le monde réel avec les ondes radio et les capteurs
Image d’entête : EL DUDUSS DE PAPEL, Toctoc (Instagram : @bytoctoc) | photographie : Kevin Lagaisse | CC BY-NC-ND 3.0
Laisser un commentaire