

A l’heure de l’ouverture des données, du « tout API », il devient facile d’exploiter, transformer, réutiliser les données mises à dispositions. De nouveaux services émergent.
Nombreux sont ceux qui voient dans l’ouverture des données une manière d’être à la base de certaines innovations d’usages, et une manière, plus mercantile, de valoriser leurs données, « ce nouvel or noir ».
Pour d’autres, il est plus difficile de concevoir la mise à disposition de leurs données, soit parce qu’ils n’y voient pas l’intérêt, soit parce qu’ils veulent rendre captifs leurs clients en empêchant leur libération.
Le web scraping est une technique qui rend le pouvoir aux utilisateurs. Son principe consiste à extraire de l’information non structurée d’un site internet afin de la rendre structurée et exploitable par un système informatique.
On développe alors des robots dont l’objectif est d’automatiser la saisie et la collecte de résultats dans des applications (sites internet, applications métier). Dans leur version intelligente, ces robots, couplés à des systèmes de workflow, observent les actions des utilisateurs afin d’apprendre ce qu’il faut faire à un instant donné. C’est le RPA ou Robotic process automation.
Dans cet article, nous nous concentrerons sur la partie scraping. Nous répondrons à la question « Comment extraire automatiquement de l’information d’un site internet qui n’a pas ouvert ses données ? ».
Pour cela, nous allons travailler avec puppeteer et Chromium sur le site http://quotes.toscrape.com/js/
Quelques usages du web scrapping
Avant cela, posons-nous et interrogeons-nous sur les usages que nous pouvons faire de cette technique. Ainsi, parmi les usages, on notera :
- L’opendata : il s’agit de rendre disponible auprès de tiers les données collectées pour qu’elles en fasse un usage à définir.
- L’interopérabilité : il s’agit ici d’intégrer le site internet à une étape d’un processus pour qu’il puisse échanger des données avec un autre système sans que les deux ne se connaissent.
- La mobilité : pendant du point précédent, il s’agit de rendre accessible une application web depuis d’autres types de terminaux. Ainsi, il est par exemple possible de faire une application mobile qui discuterait avec un système automatisant les saisies dans une application non prévue pour l’usage mobile.
- L’archivage de sites internet : avec ce type de technique il est possible d’automatiser la navigation et l’enregistrement du site et de ses ressources afin d’en conserver une représentation. Cela peut prendre différentes formes : enregistrement des fichiers reçus lors de la navigation c’est à dire fichiers html, css, js ou prise de copies d’écrans, …
- La surveillance de mises à jour de sites internet : il s’agit de vérifier périodiquement la publication de nouvelles informations et les modifications d’informations existantes comme par exemple les informations sur les prix d’un produit afin d’en mesurer la variation ou les comparer avec d’autres sites internet.
Les différents moyens de publier de l’information sur un site internet
Entrons maintenant dans le vif du sujet. Avant de collecter toute donnée, nous devons observer comment fonctionne le site Internet auquel nous nous attaquons et plus précisément par quels moyens sont publiées les informations qui s’y trouvent. Pour simplifier, je dirais qu’il y a deux manières d’afficher de l’information sur un site internet:
- de manière statique : le site internet publie de l’information dans le contenu de la page affichée.
- de manière dynamique : le site internet publie l’information sur sa page via un script exécuté côté client qui va collecter l’information de manière dynamique (appel API, résultat d’un calcul en fonction d’un comportement de l’utilisateur). La page principale est alors une coquille vide, au moins en partie, et elle est remplie dynamiquement par l’exécution de code.
Pour la partie mise en oeuvre, nous allons extraire les contenus du site de citations. A destination des développeurs, le site propose les deux méthodes sus-citées de génération de son contenu.
Dans mon navigateur, le site ressemble à cela :
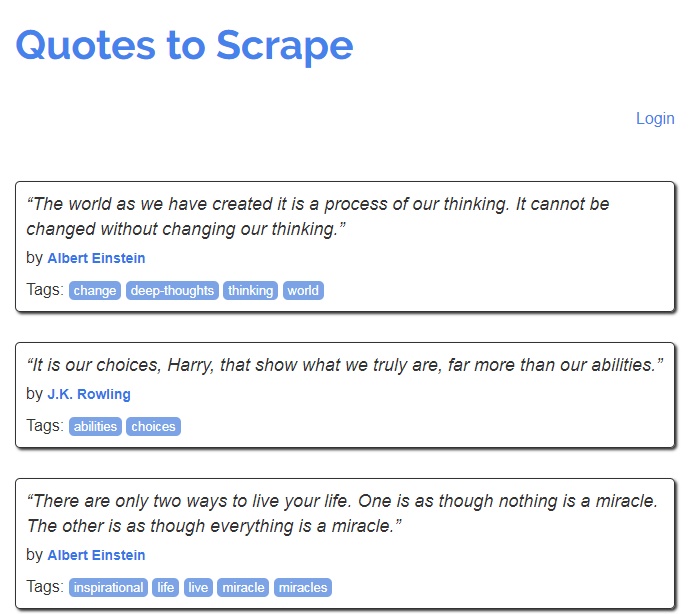
Dans sa première version, le contenu est directement généré dans la page html côté serveur. Il est alors très facile d’extraire le contenu avec un simple wget :
Si j’ouvre le fichier téléchargé, j’obtiens le résultat suivant :

Ce n’est pas très joli, mais le résultat est satisfaisant puisque vous pouvez en lire le contenu. Il est inutile donc de charger d’autres ressources, telles que les images, les feuilles de style et le javascript. Il est possible de travailler ensuite sur le contenu pour en extraire les informations souhaitées.
Si l’on prend un contenu généré dynamiquement (via javascript) et qu’on lance la même commande :
Nous obtenons ceci :

Zéro contenu !? C’est tout à fait normal, puisque c’est le javascript qui génère le contenu et le place dans la page web. Notre premier outil de web scraping, wget, n’offre pas la possibilité d’exécuter le code javascript. C’est là tout l’intérêt d’une solution qui utiliserait un navigateur complet.
Ainsi, on notera que pour scraper un site internet, il convient de bien choisir ses outils.
Quelques exemples d’outils de web scraping
Parmi les outils, Chromium est en train de rebattre les cartes. De nombreux projets majeurs ont annoncé qu’ils arrêtaient de poursuivre leur développement suite à la sortie de la dernière version de Chromium incluant des fonctionnalités d’automatisation.
Chromium est à la base de Chrome, bien connu de tous comme étant un navigateur complet, supportant les fonctionnalités avancées de CSS et de javascript. Il risque de rapidement supplanter toutes les autres librairies qui n’offrent pas ce type de fonctionnalités ou fonctionnant sur des moteurs de navigation plus anciens (phantomjs par exemple).
Il est cependant possible d’utiliser d’autres outils pour scrapper des sites. Les plus basiques, ce sont wget ou curl. Ne vous attendez pas à récupérer autre chose que du html brut comme vu plus haut. Exit donc les résultats de calcul en javascript, la navigation dynamique gérée par un module javascript… Ici, vous récupérez de la donnée brute par un appel direct. Certains sites (via leur CDN) détectent ce type de comportement (via le user agent, ou via la détection de l’activation du javascript) et bloquent ce type d’initiative.
D’autres sont de très bonnes alternatives telles que :
- phantomjs associé à casperjs : phantomjs fonctionne sur une ancienne version de WebKit. Le projet est arrêté suite à la sortie de la dernière version de Chromium.
- Selenium associé à tous les navigateurs : très utilisé dans le domaine des tests unitaires, Selenium permet d’automatiser des tâches dans le navigateur.
- Cheeriojs, Scrapyjs, BS4 pour python : Ces libraires extraient le contenu de la page mais ne chargent pas d’autres ressources comme un navigateur le ferait. Ils sont quoi qu’il en soit très utilisés dans de nombreux projets.
Mise en oeuvre
Comme précisé au début de l’article, nous nous efforcerons de répondre à la question « Comment extraire automatiquement de l’information d’un site internet qui n’a pas ouvert ses données ? » par la pratique.
Pour cela, nous allons travailler avec puppeteer et Chromium sur le site http://quotes.toscrape.com/js/.
Installation de nodejs
L’installation de node est détaillée à l’adresse suivante : https://nodejs.org/en/download/package-manager/
A noter que node embarque NPM, le gestionnaire de paquets node.
Pour ma part, utilisant une base de debian, j’ai exécuté les commandes suivantes :
Initialisation du projet
L’initialisation du projet se fait en créant un répertoire dédié dans lequel nous allons travailler :
Et comme vous êtes poli, vous répondez aux questions (elles n’ont pas d’influence ici mais sont indispensables à la bonne gestion du projet).
Installation de puppeteer
Pour cet exercice, nous allons utiliser puppeteer. Puppeteer est une bibliothèque node offrant des interfaces pour Chrome et Chromium. Ces interfaces permettent de piloter en javascript le comportement du navigateur.
L’installation de puppeteer embarque une installation de Chromium. C’est parfait car cela nous évitera une configuration avancée inutile.
L’installation de puppeteer se fait via la commande :
L’installation est supérieure à 100 Mo incluant Chromium.
Travaillant sur une machine sans écran, il m’a manqué de nombreuses dépendances liées aux librairies graphiques. Le lien ci-après m’a été utile :
et notamment la commande suivante pour savoir ce qu’il me manquait :
Notre Hello World
La première étape est de vérifier que tout fonctionne. Pour cela nous allons faire une copie d’écran du site toscrape.com.
Nous créons un répertoire screenshots dans le lequel se trouvera notre copie d’écran :
Puis nous créons un fichier que l’on nommera scrape.js qui contiendra les instructions suivantes :
Voici ce que fait le code:
- Importation et initialisation de puppeteer;
- Déclaration d’une fonction asynchrone
scrape; - Lancement d’une instance du navigateur sans qu’il ne s’affiche
headless = true; - Ouverture d’une nouvelle page du navigateur;
- Initialisation de la vue de la page, ici 1920 sur 2160 (écran en mode portrait);
- Navigation vers la page du site http://toscrape.com et attente que tout soit bien chargé;
- Prise d’une copie d’écran et sauvegarde vers le chemin
screenshots/toscrape.png; - Fermeture de l’instance du navigateur;
- Enfin, appel de la fonction
scrape().
Lançons le script de la manière suivante :
Nous obtenons ce résultat :
TADAAA ! Nous venons de scraper notre premier site web.
Scraping du site internet de citations
Dans cette seconde partie, nous allons extraire le contenu du site de citations sous forme de données. Le site propose différentes méthodes de génération de contenu pour exercer son automate. Comme expliqué en introduction, nous allons utiliser la version dont le contenu est généré par du javascript.
Pour commencer, nous allons observer le site en question. Il s’agit d’une page contenant les citations. Chaque citation est composée d’un texte, d’un auteur et d’une série de mot-clés. Le site est paginé. On accède à la page suivante en cliquant sur le bouton « Next » et ainsi de suite.
Dans cet article, je vais laisser de côté la pagination pour me concentrer sur l’extraction de contenu.
Pour commencer, et par praticité , nous allons définir une citation comme ceci :
Nous allons ensuite créer une boucle sur chaque citation affichée sur la page.
Avant de nous lancer dans l’écriture du code, nous allons inspecter la source de la page afin de déterminer comment sont structurées les citations dans le contenu de la page (clique droit sur un élément > Inspecter).
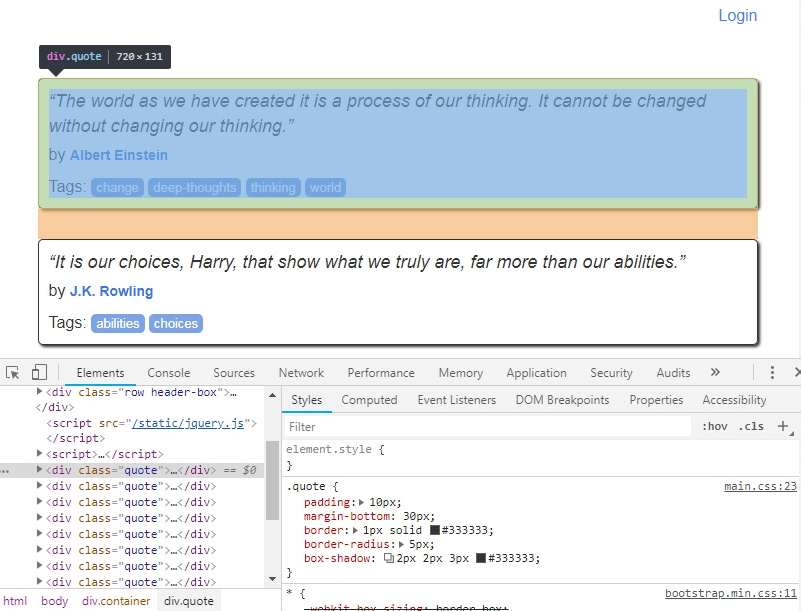
Ici, on remarque que chaque citation est contenue dans une div qui porte la classe quote. Nous allons donc lancer une requête dans le contenu de la page pour obtenir toutes les div.quote de notre document et enregistrer cela dans un tableau.
Un petit tour dans la documentation de puppeteer nous permet d’écrire :
Nous avons donc dans elements des ElementHandle de chacune des citations de la page.
Dans la suite, nous allons itérer sur ces élements afin d’en extraire ce qui nous interesse. Pour cela, retournons faire un tour dans la source de la page.
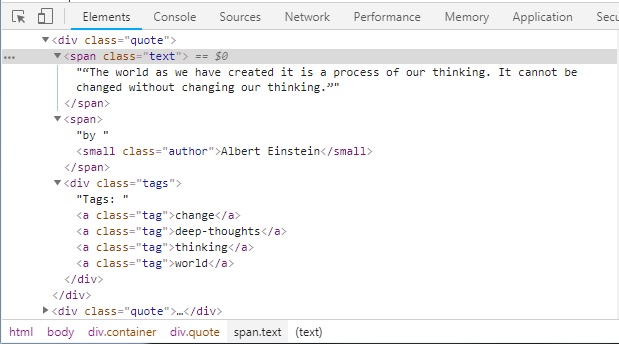
On remarque que le texte des citations se trouve à l’intérieur d’une balise qui porte la classe text, le nom de l’auteur à l’intérieur d’une balise portant la classe author, et les tags tags. Et c’est comme cela pour chacune des citations. Nous écrivons donc :
- On boucle pour chaque
elementdeelements; - Dans cet élément, on sélectionne l’élément qui a la classe
text. On en extrait le contenu que l’on débarrasse des éventuels espaces en trop; - Dans cet élément, on sélectionne l’élément qui a la classe
author. On en extrait le contenu que l’on débarrasse des éventuels espaces en trop; - Dans cet élément, on sélectionne l’élément qui a la classe
tags. Ici on ne fait rien. Il contient un ensemble d’éléments de classe tag. Nous allons d’ailleurs modifier cette ligne juste après; - Enfin, nous loguons dans la console le texte et l’auteur de la citation.
Comme précisé précédemment, intéressons-nous aux tags. La source de la page nous indique que pour chaque citation, les tags sont dans des balises a qui portent chacune la classe tag. Une manière de faire serait de refaire une boucle sur chaque élément de la variable tags récupérée précédemment et de renseigner une tableau. Il se trouve que puppeteer propose la fonction pour le faire. Notre code devient:
Ce code sélectionne tous les élements de classe tag et les met dans un tableau. Nous avons un talbeau d’ElementHandle de type a. La partie ar => ar.map(a => a.text) extrait pour chaque élément du tableau le texte contenu dans la balise a.
Une fois ceci fait, il ne nous reste plus qu’à stocker le contenu dans un tableau. Le code complet devient :
Vous pouvez tester le résultat avec la commande suivante :
Cela donne le résultat suivant :
Nous disposons donc des citations sous une forme structurée et pouvons les utiliser dans notre projet suivant.
Bonus Track : Mettre à disposition les données via une API Rest
Vous êtes arrivé jusqu’ici. Bravo !
Pour la suite, nous allons publier sous une forme structurée les données fraîchement collectées.
Pour cela, nous allons utiliser express. Express est un module Nodejs. Il fournit un ensemble de fonctionnalités pour les applications Web et mobiles.
Il dispose notamment d’outils pour HTTP permettant d’accélérer la création d’API.
Depuis le terminal, installons express :
Nous allons créer une série de répertoires :
routes: Ce répertoire contiendra tous les fichiers permettant de gérer les points d’entrée de notre application. Les routes redirigeront le traitement vers le bon contrôleur.controlers: Ce répertoire contiendra tous les fichiers permettant de gérer les traitements de notre application. Le contrôleur réalise le traitement en lisant ou écrivant les données depuis un ou plusieurs modèles.models: Ce répertoire contiendra tous les fichiers permettant de gérer les données de notre application.
Nous allons ensuite déplacer le fichier scrape.js dans le répertoire contenant les modèles :
Nous allons modifier le fichier scrape.js et faire en sorte que la fonction scrape() retourne le tableau des résultats en ajoutant return mydata; à la fin de la fonction. Ensuite nous allons modifier la dernière ligne. Au lieu d’appeler scrape(); nous allons exporter la fonction pour qu’elle puisse être utilisée dans un autre module :module.exports = scrape ;
Dans le répertoire controlers, nous créons un fichier quoteControler.js qui contiendra :
Nous créons ensuite un fichier quoteRoute.js dans le répertoire routes qui contiendra le code suivant :
Le code des fichiers précédents permet de faire en sorte que quand le point d’entrée /quotes de notre API est appelé avec la méthode GET, l’application appelle la méthode list_all_quotes qui déclenche le scraping du site et retourne les résultats sous forme d’une réponse formatée json.
Enfin, pour que tout cela fonctionne, il nous faut un moyen de démarrer l’application pour qu’elle écoute les requêtes entrantes.
Nous créons donc un fichier server.js à la racine de notre projet avec le code suivant :
Il n’y a plus qu’à tester.
Pour cela, nous lançons notre application de la manière suivante :
Le serveur est démarré si ceci apparaît :
Avec notre navigateur, rendons-nous à l’adresse de notre serveur, ici en l’occurrence http://localhost:8080/quotes. Le résultat est stupéfiant :
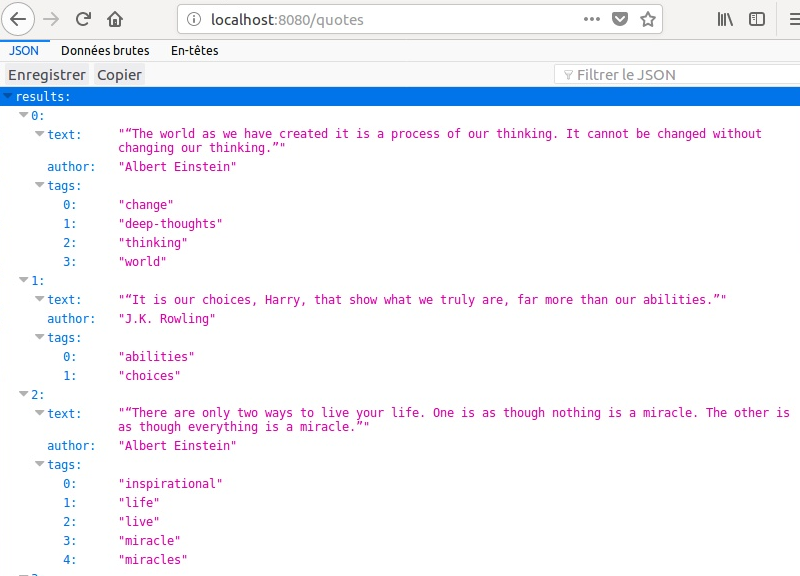
Conclusion
Vous venez d’extraire automatiquement vos premières données structurées à partir d’informations non structurées publiées sur Internet. Maintenant que vous avez ces données, vous pouvez les retravailler et les réutiliser dans vos programmes. Vous avez aussi pu créer une API pour mettre à disposition des données qui n’étaient initialement pas structurées.
Evidemment, vous remarquerez de nombreuses pistes d’optimisation. Parmi celles-ci :
- La mise en cache des données : En fonction de la fréquence de collecte des données, il devient vite indispensable de mettre en place un mécanisme de cache. Cela permet de ne collecter que les nouvelles données ou de ne les rafraîchir que sous certaines conditions;
- La prise en compte du temps de traitement : le web scraping imite l’utilisateur qui navigue sur un site internet. Un scénario de navigation élaboré pourra nécessiter du temps. Il conviendra donc de rendre asynchrone le traitement de la demande;
- La validation des données : les données des applications qui sollicitent l’API tout comme les données collectées des sites internet doivent être validées afin de s’assurer que les données saisies ou reçues correspondent bien aux types attendus;
- La gestion des erreurs : le scrapping dépend de nombreuses variables en cela qu’il s’agit de travailler avec un site dont on ne maîtrise pas grand chose. Ainsi il est indispensable de prévoir tous les types d’erreur auquel nous pouvons être confrontés (coupure réseau, instabilité de Chromium, modification de la structure du site internet distant, changement des types des données …);
- et bien d’autres encore…
Avant de nous quitter, sachez que si vous cherchez à automatiser le téléchargement de fichier, il y a actuellement une limitation qui n’est pas des moindres : il est impossible de télécharger un fichier avec Chromium et puppeteer pour l’instant. Certains ont trouvé des solutions de contournement qui ne fonctionnent que dans des cas très spécifiques. La fonctionnalité est heureusement prévue. Elle est en priorité 1 et devrait arriver prochainement.
Image d’entête : EL DUDUSS DE PAPEL, Toctoc (Instagram : @bytoctoc) | photographie : Kevin Lagaisse | CC BY-NC-ND 3.0
Laisser un commentaire